LLM Post-Training: A Deep Dive into Reasoning Large Language Models
This survey provides a systematic exploration of post-training methodologies, analyzing their role in refining LLMs beyond pretraining, addressing key challenges such as catastrophic forgetting, reward hacking, and inference-time trade-offs.
LLM Post-Training: A Deep Dive into Reasoning Large Language Models
这篇论文主要探讨了大型语言模型(LLM)的后训练(Post-Training)技术,特别是如何通过微调(Fine-Tuning)、强化学习(Reinforcement Learning, RL)以及推理时(Test-Time Scaling)扩展等方法来优化模型的推理能力、提升事实准确性,并更好地与用户意图和伦理要求对齐。
这篇文章的contribution:
- A comprehensive and systematic review of post-training methodologies for LLMs, covering finetuning, RL, and scaling
- A structured taxonomy of post-training techniques, clarifying their roles and interconnections
- A practical guidance by introducing key benchmarks, datasets, and evaluation metrics essential for assessing post-training effectiveness
解释Test-Time Scaling:OpenAI o1 技术初探1:整体框架,利用Test-Time Scaling Law提升逻辑推理能力
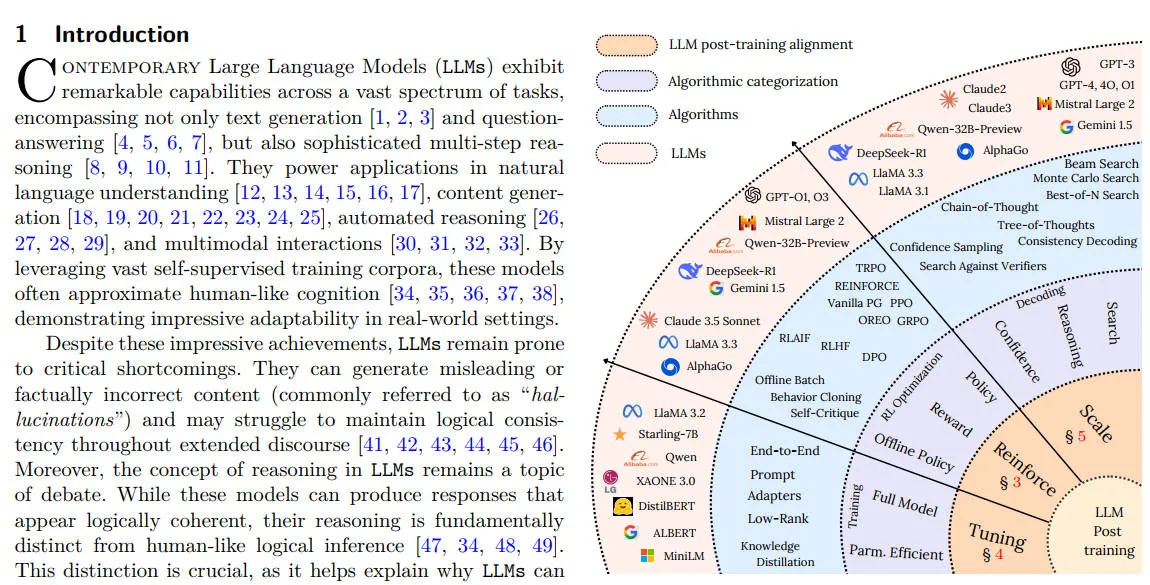
LLM 已在自然语言处理 (NLP) 领域取得了显著成就,不仅能进行文本生成和问答,还能执行复杂的多步推理任务。 传统的预训练 (Pre-training) 仅提供了广泛的语言基础,但通过后训练方法,可以进一步提升模型的推理能力、准确性及与用户意图的对齐。 主要挑战包括“幻觉”(hallucination,模型生成错误或误导性内容)、逻辑一致性差、推理能力与人类逻辑推理的根本区别等。 后训练阶段主要通过微调、强化学习、推理时扩展等手段克服这些挑战。
关键方法论:
微调(Fine-Tuning):
- 通过在特定任务或领域数据集上更新模型参数来实现任务特定的学习,但需权衡过拟合风险和计算成本。
- 采用的技术包括 LoRA(低秩适配 Low-rank adaption of LLM)、适配器 (Adapters) 以及检索增强生成 (RAG) 等。
强化学习 (Reinforcement Learning, RL):
- 不同于传统 RL,LLM中的RL涉及从大词汇表中选择token,面临稀疏、主观、延迟的反馈,需平衡多重目标。
- 主要方法有 RLHF(从人类反馈的强化学习)、RLAIF(从 AI 反馈的强化学习)、DPO(直接偏好优化)等。
推理时扩展 (Test-Time Scaling):
- 通过动态调整推理时的计算资源来提升模型适应性,例如链式思维 (Chain-of-Thought, CoT)、思维树 (Tree-of-Thought, ToT) 以及蒙特卡洛搜索 (Monte Carlo Search)。
论文是2025年2月28日的,Table 1是一个大模型总览列表,直观地对比不同模型的强化学习方法和架构特性。
通过RL技术优化LLMs推理能力,整体分为四个核心步骤:
Supervised Fine-Tuning (SFT) 监督微调 SFT是强化学习过程中的第一步,通过高质量的人类标注数据集对预训练语言模型进行微调,目标是让模型掌握基础的格式和风格要求,为后续的强化学习打下良好的基础。 操作:模型初始化➡️数据集准备(人工标注的高质量数据集)➡️监督学习 这一步是为了提高模型对具体任务的响应能力,确保模型的输出符合人类语言的格式和逻辑标准
Reward Model (RM) Training 奖励模型训练 在强化学习中,奖励模型负责评估模型输出的质量,提供奖励信号 (Reward Signal) 来指导模型的行为。 奖励模型通过模拟人类的偏好来打分,使模型生成的文本尽可能接近人类期望的输出。 操作:从已微调的模型中生成大量响应示例,让人类评估这些响应,给出偏好标签,使用这些偏好数据训练一个模型 这一步是为了通过这些奖励信号,模型可以在强化学习阶段更好地对其人类偏好
RL Fine-Tuning 强化学习微调 通过强化学习的策略梯度方法 (Policy Gradient) 调整模型的策略 (Policy),使其最大化奖励模型的输出。 操作:使用SFT过的模型作为基础策略,通过模型在不同的输入上生成多个响应,奖励模型为每个响应生成奖励分数,反映这些响应与人类偏好的匹配度,使用策略梯度方法 (例如 PPO、GRPO) 更新模型参数,使模型倾向于生成高分响应。
Reward Modeling and Alignment 奖励建模和对齐 在强化学习微调的过程中,通过构建复杂的奖励函数 (Reward Function) 引导模型生成符合人类期望的输出。 操作:奖励模型不仅仅关注最终输出的准确性,还会引入一些过程性奖励,比如在CoT中,每一步推理都可以获得奖励,确保整个推理链条的逻辑连贯性;通过人工标注的偏好数据和自动化的评价指标来细化奖励信号。 这一步主要解决模型输出的“安全性”、“有用性”和“上下文适应性”等问题。